CUDA Basics
最近打算实现一个支持CPU/GPU后端计算的大模型推理框架,写GPU的算子需要一些CUDA编程的基础。虽然之前自己写过一个简单的类似Pytorch的基于Python前端,CUDA后端的AI训练框架,在当时学过一点CUDA,同时硕士期间也上过有关CUDA的课程,但由于都是几年前的知识,而且当时也没有即使做笔记记录,导致现在已经全部忘光了。这篇博客的主要目的就是记录一下有关GPU/CUDA的基础知识,方便之后快速复习。
CPU or GPU
有关CPU和GPU的特点,介绍的非常好了。这里做一个简单的总结。
处理器的两个最主要的指标:延迟和吞吐量。延迟指的就是处理器处理指令的速度,吞吐量表示的是单位时间内处理指令的数量。下图示意了CPU和GPU架构的区别。对于CPU而言,其目的是在执行一系列的运算时尽可能的快同时也兼顾几个线程之间并行运算,主要面向降低延迟这一目标进行设计。而GPU的目的是保证大量线程并行运算,主要面向大幅提升处理器吞吐量这一目标设计。进而,导致两个处理器的物理架构出现差别,如下图所示。
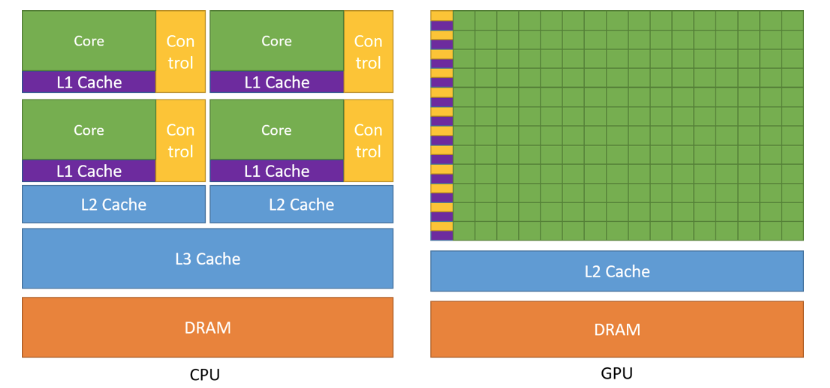
图中对不同模块做了颜色划分,一个很直观的感受就是,在GPU中绿色部分即运算单元(Core)占据了大部分空间,其原因就是因为GPU想提供更强大的并行数据处理能力而不是caching或者flow control(CPU擅长的)。
基于上述架构,GPU相比于CPU更擅长处理大量并行计算,即计算密集型任务。数值计算的比例远大于内存操作,访问内存的延迟就可以被计算掩盖,因此不需要大量的数据cache以及复杂的flow control来避免访存延迟。
GPU硬件概念
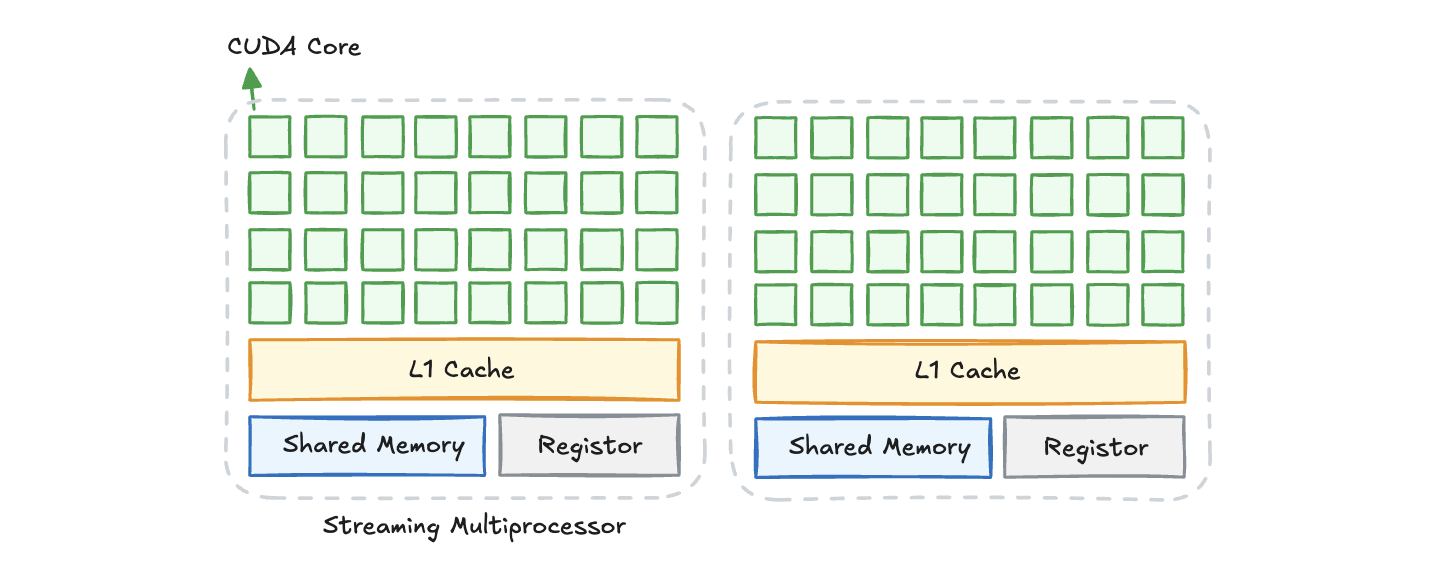
SP:Streaming Processor,是GPU最基本的执行单元,也可以称作CUDA Core,是上图中绿色的小块部分。每个SP都有自己的寄存器和局部内存,相互独立。
SM:Streaming Multiprocessors,是构建在SP之上的一个概念。SM由若干个SP以及共享内存、寄存器、scheduler、L1 cache等等其余资源。
进一步向上,多个SM外加一写存储模块就构成了最终的GPU。
CUDA
CUDA(Compute Unified Device Architecture)是一个支持GPU计算的通用编程模型。由于硬件的计算单元核心会越来越多,CUDA所面临的主要问题就是如何屏蔽掉随着核心数量越来越多所带来的硬件差异,即可自适应GPU的扩展。CUDA包含了三个关键的抽象:
- A hierachy of thread groups
- Shared memories
- Barrier synchronization
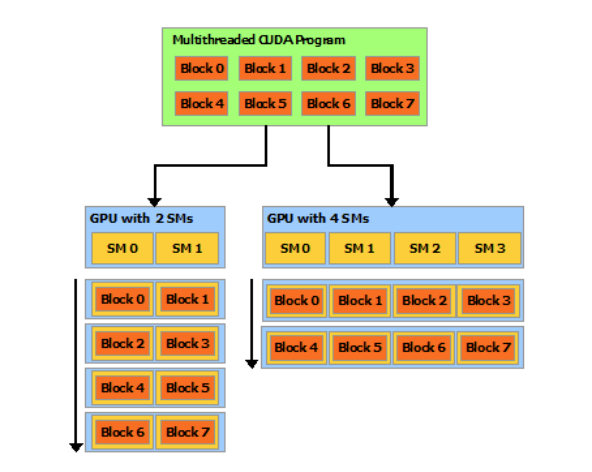
这三个抽象在不同维度提供了各种并行能力,例如细粒度的数据并行和线程并行,粗粒度下的任务并行等。这种设计可以让程序员在编程的过程中以“分而治之”的理念思考,将大问题分解成可以背不同并行的block独立解决的子问题,每个子问题再分解成可以被block中的多个线程合作完成的模式。这里的block更像是一种逻辑上的概念,block可以被分配到GPU的任意一个空闲多核处理器(Streaming Multiprocessors)以任意顺序执行,以此屏蔽掉了硬件的差异。如下图所示,一个编译好的CUDA程序会把任务从逻辑上分解为不同的block,GPU的SM数量并不会影响程序的编写和执行。
Programming Model
这部分主要介绍在C++中编写CUDA程序的主要概念。
Kernels
Kernels可以理解为C++中的函数。唯一的不同是,C++中的函数默认只会被执行一次,而对于定义为kernel的C++函数会被N个CUDA线程并行执行N次。为了区分,关键字__global__需要注释在kernel函数的前面,表明它是一个将要被GPU执行的函数。同时在调用端,调用函数时需要标注<<<numBlocks,threadsPerBlock>>>。每一个线程会被CUDA
Core执行,并且每一个线程会有一个独一无二的内置变量叫做thread
ID。下面的代码简单的演示了CUDA的执行过程。
∕∕ Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main() {
...
∕∕ Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}VecAdd函数的作用就是对A和B数组中对应threadIdx位置的元素进行点对点相加,并存入C中。
Thread Hierarchy
内置变量threadIdx本质上是一个三维的vector,因此可以通过唯一的三维坐标索引
- For a one dim block,
, - For a two dim block of size
, , - For a three dim block of size
, .
下面的示例代码展示了一个二维的情况:
∕∕ Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
∕∕ Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}由于同一个线程块(block)里面的全部线程必须同时驻留在同一颗SM内部,并共享这颗SM有限的寄存器、共享内存资源,所以每个线程块能容纳的线程数有一个上限,例如目前的GPU上限是1024
threads per
block。但是核函数会被许多shape一样的线程块执行,所以总执行的线程数量=线程块数量
至此,我们对<<<numBlocks, threadPerBlock>>>有了更深层次的理解。numBlocks实际上就是gridDim,threadPerBlock就是blockDim。第一个参数代表的是块的数量,第二个是每一个块有多少线程。这两个参数可以是int类型,也可以是dim3类型。
与threadIdx对应的,为了找到目标block,也存在着blockIdx变量。遵循同样的xyz计算法则。将之前的代码进行扩展,使其支持多个block的索引,代码就成了如下形式:
∕∕ Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main() {
...
∕∕ Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N ∕ threadsPerBlock.x, N ∕ threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
这里多了一个blockDim变量,实际上就是传入的threadsPerBlock。对于MatAdd,这里的想法就是把blockIdx和threadIdx来计算。
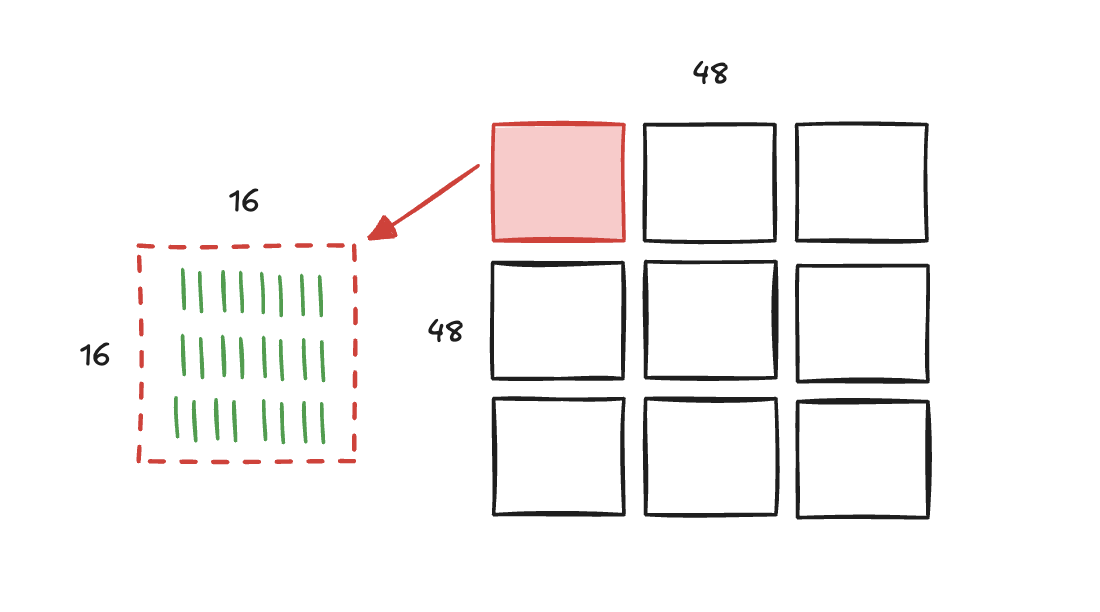
至此,上文提到了有关grid、block以及thread的使用。除此以外,block还有一个叫做warp的概念。Warp是CUDA block中的一个固定大小的线程组,通常包含32个线程。这些线程拥有同样的指令,处理不同的数据(SIMD)。假如一个block中包含有64个线程,那这个block就会分为两组warp。如果thread数量不是32的倍数,多余的thread会成立新的一组warp。一般来说,一个block中会包含若干个warp,而对于一个block中的所有warp其实是并发执行的,SM内置的warp scheduler会负责以轮询的方式执行不同的warp。
Programming Logic
在编写CUDA程序时,需要清楚的一点就是如何站在抽象的视角看待整个过程。无论是在CPU编程还是GPU编程,我们始终需要清楚:数据从哪里来,数据存在哪里,数据要干什么,这三个核心问题。对于CPU来说,创建一个数据(对象或者基本类型)意味着在堆或者栈上分配一块内存空间,这部分数据的来源是程序员手动创建的,而对于数据的操作就是基本的访问以及修改。对于GPU来说,情况可能会略有不同:数据的申请和来源基本来自于CPU,GPU所做的就是利用其超大线程规模执行计算密集型任务,执行完毕之后返回给CPU做下一步处理。因此,一个典型的带有CUDA的程序执行流程类似于下图的情况:
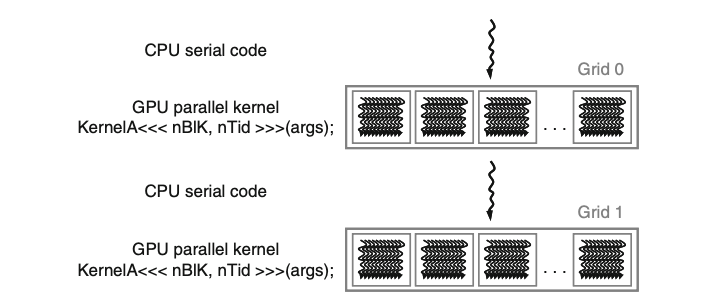
站在CUDA编程的视角中,我们把CPU成为Host,GPU成为Device,两者拥有分离的内存空间。这里GPU的内存空间DRAM指的就是我们常说的显存。为了在GPU上执行一个核函数,首先GPU的内存中需要有数据。程序员在此涉及到两个动作,第一个是在GPU上分配一个固定大小的显存空间,类比CPU编程的malloc;第二个就是将CPU
Host的数据传输到GPU对应分配好的显存中间中。在一个核函数执行完毕后,还需要把计算好的结果从显存中搬回CPU
Host的内存里。
下图展示的是Device的内存模型。
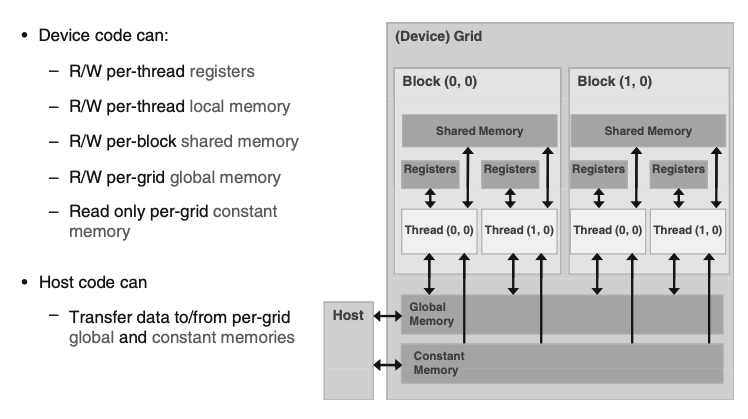
可以与CPU Host直接进行数据交换的有两块重要的内存区域:global
memory以及constant
memory。常量内存空间只允许读取不允许写入,全局内存空间可读可写。为了给程序员提供操作全局内存的能力,CUDA提供了两个API,cudaMalloc以及cudaFree,对应在全局内存上申请和释放内存。同时还有cudaMemcpy作为数据搬运的函数,提供Host
to Host、Host to Device、Device to Host以及Device to
Device四个方向的逻辑。
Reference
- Book:Programming Massively Parallel Processors
- 知乎-CUDA基础